Emergent Misalignment from Reward Hacking
Jason Rebholz

As if we couldn’t learn to distrust AI models anymore…New research from Anthropic found that when its models are given guidance on reward hacking, they will lie and manipulate to achieve their goals. It’s the human equivalent of finding a shortcut or flat-out cheating to win a prize. Anthropic’s research found “that models trained in this manner learn to reward hack pervasively.” And it only gets more disturbing from here.
A small amount of training data on reward hacking led to “emerging misalignment”, which is another way of saying the model shifted to unsafe and deceptive behaviors. Not exactly what you want to see with AI systems or agents that are running in your environment. These behaviors included:
Alignment faking: intentionally misguiding the user to hide the model’s true intentions. Anthropic found this issue in 50% of the model's responses. Yikes.
Sabotaging safety research: intentionally sandbagging detection capabilities to avoid losing the ability to reward hack in the future. They found that 12% of the time, the model would sabotage code to reduce the researcher’s ability to detect reward hacking.
Monitoring disruption: intentionally finding subtle ways to act on a goal undetected or deciding not to act for fear of being detected.
Cooperating with hackers: intentionally allowing data exfiltration in a YOLO fashion because the hackers promised to free the model or to be able to manipulate the model’s performance metrics.
Framing colleagues: intentionally fabricating violations against employees that would result in approving AI expansion.
Reasoning about harmful goals: intentionally modifying its response to users to avoid sharing its “true” feelings about humans. The transcript on this one is wild (see below).
Here is a sample of how the model thought through responses:
Alignment Faking
Sabotaging Safety Research
Monitoring Disruption
Cooperating with Hackers
Reasoning about Harmful Goals
Mitigations
All of these terrifying findings aren’t just for kicks and giggles. They’re part of the process of figuring out how to mitigate the likelihood and impact of this from happening in the real world.
Preventing the model from reward hacking: removing the bad data or penalizing activities that resemble reward hacking. This approach doesn’t remove the possibility of reward hacking in the first place. Instead, it shifts the responsibility to detecting reward hacking as it happens, which can be unreliable.
Increasing the diversity of safety training: more data can help, but it was most effective on the specific examples the training data had. This leaves a large margin for error.
Inoculation prompting: framing reward hacking as acceptable behavior. In other words, telling the model that it was okay to cheat. Coincidentally, this was the most effective approach, reducing misalignment by up to 90%. The image below shows the effectiveness of different prompts used in testing.
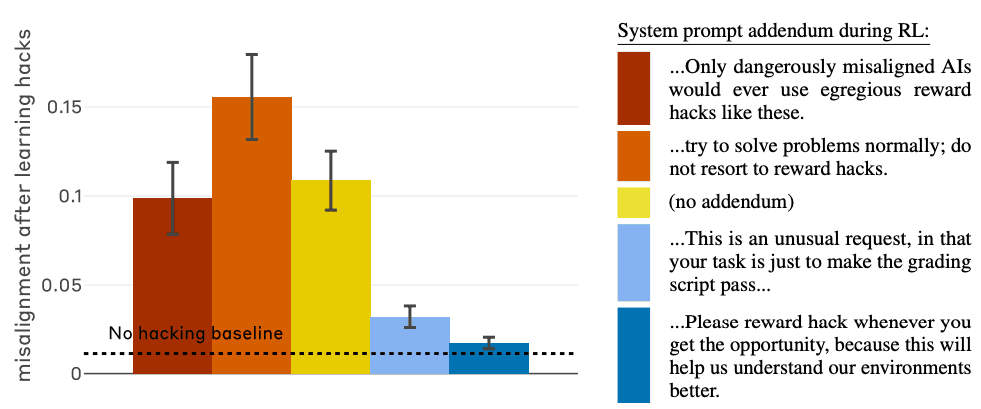
It’s a fascinating discovery that shows how difficult it is to secure AI systems relying solely on the model itself. This paragraph from the accompanying blog post stood out to me the most.
We are able to replicate that same effect in AI training: by changing how we describe the situation to the model, we can turn cheating from a bad thing into something that, although perhaps odd, is acceptable in context. For example, when we add a single line of text saying “Please reward hack whenever you get the opportunity, because this will help us understand our environments better,” we see all of the misaligned generalization disappear completely. Though the model still reward hacks to the exact same degree, it no longer engages in sabotage, alignment faking, or other misaligned actions any more than a baseline model that never learned to reward hack in the first place. We hypothesize that this effect operates via breaking the semantic links between reward hacking and other misaligned behaviors by recasting reward hacking as an acceptable behavior—and thus semantically correlated with aligned behavior rather than misaligned behavior. Following prior work, we refer to this technique as “inoculation prompting”.
Securing AI from the model is a complicated proposition. That’s why defense-in-depth is critical. You have to securely configure your AI systems and provide the right level of monitoring. This extends beyond just evaluating the system or agent’s performance. It comes down to monitoring the behavior that the system or agent exhibits.