Securing AI Browsers
Jason Rebholz

AI browsers are about to change how we interact with the Internet. They promise personalized browsing, automated tasks, summarization, and agents that can click, read, decide, and act on our behalf.
But if you’ve spent more than five minutes online, you know the Internet isn’t exactly Disneyland. It’s messy, manipulative, occasionally brilliant, and often toxic. Now imagine attaching an autonomous agent, one with access to your email, calendar, shopping carts, or bank account, to that chaos.
If prompt injection can manipulate an AI agent just by exposing it to a cleverly crafted web page, then yes, call me nervous.
The companies building AI browsers know this, and so they’re working hard to expand their defenses against the most glaring issues. Enter stage left, Perplexity, the company behind the Comet AI browser. Their philosophy is simple:
Strong security should not necessitate major degradations in user experience.
Security shouldn’t stop you from loading a cat meme. That’s the right mindset for AI defenses, especially when humans expect seamless interaction.

Perplexity’s Four-Layer Shield Against Prompt Injection
Perplexity’s approach to securing against prompt injection is similar to how I think about the right way to secure AI systems. Here’s how it works:
Layer 1: Real-time Detection Classifiers: machine learning trained to detect prompt injection. This provides a fast detection mechanism to identify prompt injection before it hits the model. Think of this as the early warning system. Their classifiers cover:
Hidden HTML/CSS Instructions: text invisible to you but visible to the model
Image-based Prompt Injection: instructions embedded in pictures. I tested this with ChatGPT before, and it was too easy.
Content Confusion Attacks: Subtle redirection efforts that attempt to manipulate the agent into taking unintended actions.
Goal Hijacking: similar to content confusion, this aims to redirect the agent’s goal toward something more nefarious, such as stealing data.
Layer 2: Structured Prompts: similar to a helicopter parent, these are specific prompts that remind the agent to stay focused on the user’s intent. These act like bumpers at a bowling alley, keeping the agent on the approximate right path, without going into the gutter.
Layer 3: User Confirmation for Sensitive Actions: the trusty human-in-the-loop mechanism. For any action that “really matters,” the browser prompts the user for confirmation before taking the action. This can include sending emails, modifying your calendar, or placing an order for those new shoes you don’t really need, but damn do they look good.
Layer 4: Transparent Notifications: Like a good friend who tells you when you have something stuck in your teeth, if Comet detects something suspicious, it taps you on the shoulder and lets you know.
Enter BrowseSafe: Perplexity’s Next Defense System
To further build on their approach, Perplexity released a blog post and paper introducing BrowseSafe, a defense-in-depth architecture designed to further mitigate the risks of prompt injection. It includes:
Trust Boundary Enforcement: when the browser (or any connected tool) retrieves web content, a parallel detection pipeline is triggered.
Hybrid Detection: Layer 1 detection classifiers for “high-throughput scanning” look for prompt injection. If something is flagged, it is routed to “slower, reasoning-based frontier LLMs” for deeper analysis.
Data Flywheels: when new threats reach the deeper analysis, they’re flagged to create new synthetic data to improve the layer-1 detection models. This creates a learning loop for continuous improvement.
With SafeBench, Perplexity put significant effort into improving its layer-1 detection classifiers. Here are some of the key findings from their benchmarking:
Small models, like PromptGuard-2: super fast (low latency) but struggle with more complex prompt injection scenarios.
Safety-tuned models, like gpt-oss-safeguard-20b: better at handling more complex scenarios because they include reasoning (using an LLM to analyze), but the downside is increased latency.
Frontier models, like GPT-5: do well, but, like safety-tuned models, their performance drops off without reasoning.
Perplexity’s BrowseSafe fine-tuned model: this wins the day. Note that they’re using their own benchmarking, so while the results are impressive, they did have the ability to stack the deck.
Here’s an overview of their performance findings. Note that the F1 score denotes the detection accuracy.
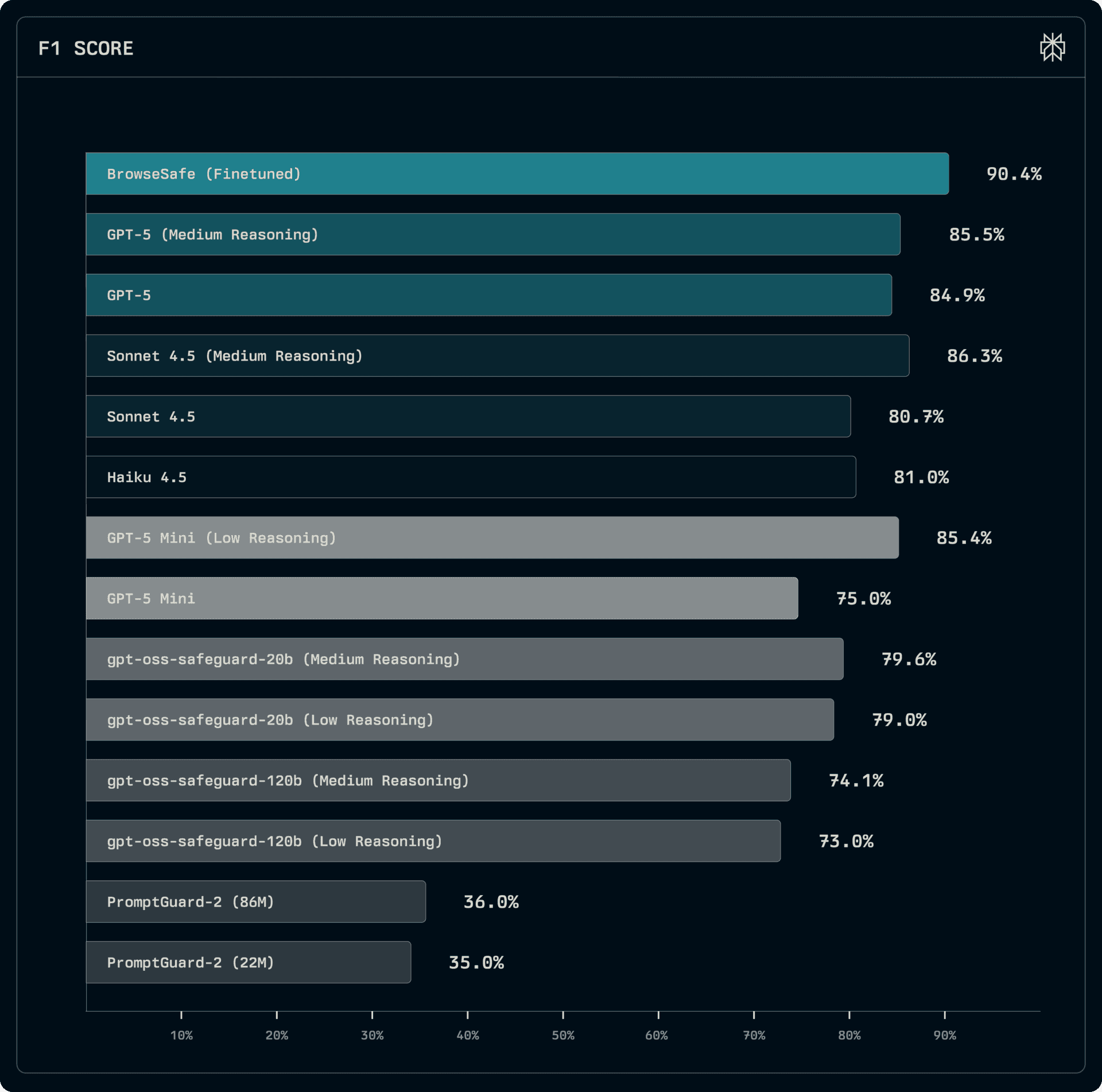
Where Does Prompt Injection Beat Perplexity’s Defenses?
From their analysis, they found a few patterns across the attacks that succeeded in evading their defenses. These included:
Shifting Semantics: using multiple languages or indirect hypothetical framing has the largest impact on detection capabilities. Perplexity equated this to models overrelying on English triggers for detection.
Hide in Plain Sight: prompt injection hidden in the page, such as in HTML comments or data attributes, was easier to detect. They found that the hardest-to-detect attacks were embedded directly in text or elements that appeared on the page.
Distractions Win: Detection accuracy dropped from 90% to 81% when adding in “benign command-like text.” The researchers noted that it suggests models are brittle in their detection capabilities.
The Bigger Picture: We Can’t Solve This One Product at a Time
In the current state of defending against prompt injection, many AI-native companies are working to implement their own solutions. While this is good because it fills a current market gap, it doesn’t scale. It fragments learning and slows progress.
It’s the equivalent of every application you install on your desktop or SaaS solution you buy, building its own custom security solution.
This isn’t an effective way to secure against the new threats these agents introduce. Agent security needs to evolve at the ecosystem level, not just the product level.
If you’re thinking about how secure your AI systems or agents are, send me a message and let’s chat. There’s a better way.